


Internet-Recherche: Wikipedia Abfragen
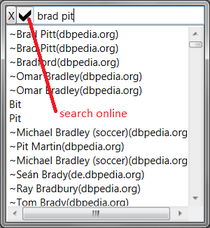
Die Spoc-Web Suche kann auf Wikipedia und andere SPARQL Server erweitert werden, indem man die "Search online" Checkbox aktiviert. Die Trefferliste wird dann aus beliebig vielen Datenquellen (u.a. der aktuellen Spoc-Web Datenbank, deutschen und englischen Wikipedia, OpenCyc und Freebase) zusammengestellt. Wird ein Wikipedia-Eintrag ausgewählt, lädt Spoc-Web dessen Daten in die eigene Datenbank herunter. Dort können sie dann inspiziert, erweitert und ggf. korrigiert werden. Heruntergeladene Daten sind u.a.:
- Artikel-Bild: als einprägsames Icon für das Objekt
- Eltern: Links zu anderen Wikipedia Artikeln und Objekten
- Kinder: Links von anderen Wikipedia Artikeln und Objekten
- Eigenschaften: alle Zahlen, Texte und Datumswerte aus dem DbPedia Datenbestand
Um die Datenmenge zu begrenzen werden Dubletten zusammengelegt und Links nur über eine Stufe hinweg verfolgt. Wie man sieht, entstehen je nach Popularität der Objekte viele Einträge in den Eigenschaften und Beziehungen. Die Knoten erhalten den Namen der Datenquelle als (Namensraum-) Präfix, um versehentliche Zusammenführungen zu verhindern. Sie können aber anschließend manuell zusammengefasst (und das Präfix gelöscht) werden:
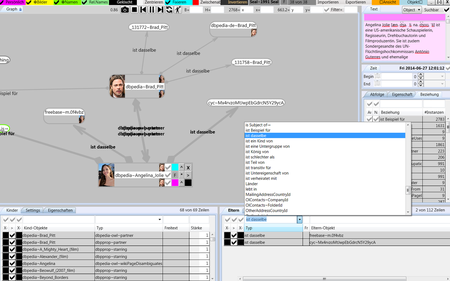
Es wird vorkommen, dass Dubletten enstehen, weil Datenquellen wie Freebase und OpenCyc nicht integriert sind. Beispiele sieht man hier sowohl für Brad Pitt als auch dessen Frau Angelina Jolie, welche beide jeweils Dubletten im freebase- und cyc-Namensraun haben. Diese Dubletten können manuell aufgelöst werden, indem man die Knoten gleich benennt. Zunächst öffnet man einen dieser Knoten (Tipp: in der Eltern-Liste auf "ist dasselbe" filtern und auf die Zeilen jeweils doppelklicken) und inspiziert ihn. Stellt such heraus, dass es sich tatsächlich um dieselben Objekte handelt, dann können sie zusammengeführt werden, indem man einem den Namen des anderen gibt. Bestätigt man die darauf folgende Sicherheitsabfrage, dann werden die Eigenschaften und Beziehungen des umbenannten Objektes auf das Original übertragen und das unbekannt Objekt als gelöscht markiert. Tatsächlich gelöscht wird es erst, wenn im Menü "Aufräumen" gewählt wird und das Objekt bereits eine Weile gelöscht ist (90 Tage, einstellbar).
Aufgrund der Popularität dieses Paares wurden bei ihrer Abfrage zusätzlich noch mehr als 350 direkt verknüpfte Objekte angelegt, sowie jeweils mehr als 30 Eigenschaften. Diese Informationsfülle mag zunächst erschreckend erscheinen, aber es stellt sich rasch heraus, dass sie sehr redundant ist, weil z.B. viele Wikipedia Klassen aus Eigenschaften und Beziehungen abgeleitet werden können.Zusätzlich sind in Wikipedia oft auch Dubletten für den Umgang mit unterschiedlichen Schriften und Schreibweisen oder Tippfehlern angelegt. Diese verweisen in der Regel auf das Original und sollten durch Umbenennen bereinigt werden. Die dabei entstehenden Links auf sich selbst sollten danach ebenfalls entfernt werden.
Das ist etwas Arbeit, aber anschließend hat man ein übersichtlicheres Modell über das gewünschte Gebiet mit allen Informationen der semantischen Community, ohne selbst Daten erfassen zu müssen.